一、注意力机制简述:
假如我要在教室里找一个人:
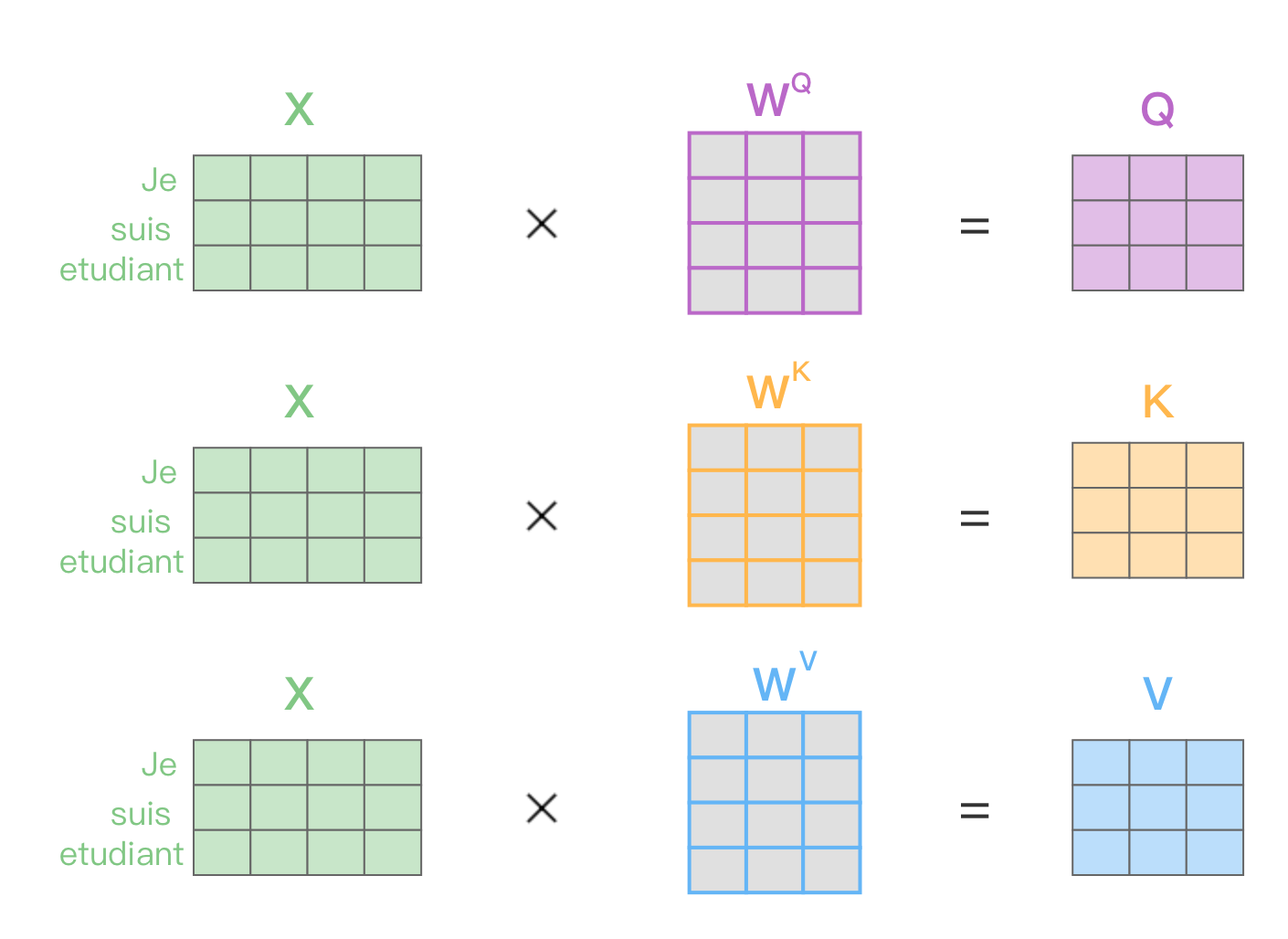
1. 首先我需要在心里想一下这个人的特征(查询Q),
2. 然后我开始扫视全班的学生(所有的键K),
3. 然后根据匹配程度给每个人打个分(注意力分数),
4. 最后我根据分数高低,从他们身上获取对应的信息(值V),分数越高,我从那个人那里听来的话就越重要
总结来说:
Q(查询):就是我心里想找的那个“目标特征”
K(键):等同于每个同学身上贴的“标签”
V(值):就是每个同学实际能提供的“信息”
二、举个例子
1. 现在用 “我爱你” 这句话举例,假设每个字用一个二维向量表示,那“我爱你”就可以表示为:
X = [[1.0, 0.0],
[0.5, 0.5],
[0.0, 1.0]]
2. 然后有三个矩阵W_Q, W_K, W_V,如下:
W_Q = [[0.5, 0.2],
[0.1, 0.6]]
W_K = [[0.4, 0.3],
[0.2, 0.7]]
W_V = [[0.8, 0.1],
[0.3, 0.9]]
3. 接下来用矩阵乘法分别计算出Q, K, V
Q = X @ W_Q
K = X @ W_K
V = X @ W_V
这就是我们要求的Q, K, V了。
4. 计算注意力分数(Q乘以K的转置)
Scores = Q @ K.T
5. 缩放(Scores 除以d_k开方)
Scaled = Scores / d_k^0.5
这里的d_k和数据的维度有关
6.通过Softmax计算出注意力权重
attention_weights = Softmax(Scaled)
7. 计算最终结果
output = attention_weights @ V
output就是最终的结果,它是输入 “X” 的新的表示
本例子中output为:
[[0.551, 0.498],
[0.544, 0.509],
[0.537, 0.521]]
每个词经过自注意力后,其新表示(Output 的每一行)都变成了整个句子中所有词 V 的加权混合。
例如“我”原本是[1,0],现在变成了[0.551,0.498],包含了“爱”和“你”的信息。
“你”也从[0,1]变成了[0.537,0.521]。
这种融合使得每个词都具有了上下文语义,这正是注意力机制的作用。
三、具体代码实现
import numpy as np
# ------------------------------
# 1. 输入数据:三个词“我”,“爱”,“你”
# 每个词用一个 2 维向量表示(为了手算方便)
# ------------------------------
X = np.array([
[1.0, 0.0], # “我”
[0.5, 0.5], # “爱”
[0.0, 1.0] # “你”
])
# ------------------------------
# 2. 定义投影矩阵 W_Q, W_K, W_V(可训练参数)
# 这里手动给出数值,模拟已经训练好的状态
# ------------------------------
W_Q = np.array([
[0.5, 0.2],
[0.1, 0.6]
])
W_K = np.array([
[0.4, 0.3],
[0.2, 0.7]
])
W_V = np.array([
[0.8, 0.1],
[0.3, 0.9]
])
# ------------------------------
# 3. 线性投影:计算 Q, K, V
# Q = X · W_Q, K = X · W_K, V = X · W_V
# 输出形状均为 (3, 2)
# ------------------------------
Q = X @ W_Q
K = X @ W_K
V = X @ W_V
print("=== 步骤1: 计算 Q, K, V ===")
print("Q (查询矩阵):\n", Q)
print("K (键矩阵):\n", K)
print("V (值矩阵):\n", V)
# ------------------------------
# 4. 计算原始注意力分数 Scores = Q · K^T
# K^T 形状 (2, 3)
# Scores 形状 (3, 3)
# ------------------------------
scores = Q @ K.T
print("\n=== 步骤2: 原始注意力分数 Scores ===")
print(scores)
# ------------------------------
# 5. 缩放:除以 sqrt(d_k)
# d_k = 2, sqrt(2) ≈ 1.41421356
# ------------------------------
d_k = Q.shape[1] # 此时 d_k = 2
scaled_scores = scores / np.sqrt(d_k)
print("\n=== 步骤3: 缩放后的分数 Scaled Scores ===")
print(scaled_scores)
# ------------------------------
# 6. Softmax 归一化(按行),得到注意力权重
# 自己实现 softmax 避免使用 scipy
# ------------------------------
def softmax(x, axis=-1):
# 减去最大值防止指数爆炸
e_x = np.exp(x - np.max(x, axis=axis, keepdims=True))
return e_x / np.sum(e_x, axis=axis, keepdims=True)
attention_weights = softmax(scaled_scores, axis=-1)
print("\n=== 步骤4: 注意力权重矩阵 (每行和为1) ===")
print(attention_weights)
# ------------------------------
# 7. 加权求和:output = attention_weights @ V
# 输出形状 (3, 2)
# ------------------------------
output = attention_weights @ V
print("\n=== 步骤5: 最终输出 Output (每个词融合全局信息后的新表示) ===")
print(output)
# 附加验证:检查每行注意力权重之和是否为1
row_sums = np.sum(attention_weights, axis=1)
print("\n=== 检查每行权重和 ===")
print(row_sums)输出:
=== 步骤1: 计算 Q, K, V ===
Q (查询矩阵):
[[0.5 0.2]
[0.3 0.4]
[0.1 0.6]]
K (键矩阵):
[[0.4 0.3]
[0.3 0.5]
[0.2 0.7]]
V (值矩阵):
[[0.8 0.1]
[0.55 0.5]
[0.3 0.9]]
=== 步骤2: 原始注意力分数 Scores ===
[[0.26 0.25 0.24]
[0.24 0.29 0.34]
[0.22 0.33 0.44]]
=== 步骤3: 缩放后的分数 Scaled Scores ===
[[0.18384776 0.1767767 0.16970563]
[0.16970563 0.20506082 0.24041631]
[0.15556349 0.23334524 0.31112698]]
=== 步骤4: 注意力权重矩阵 (每行和为1) ===
[[0.33614837 0.33310516 0.33074647]
[0.32184448 0.33343385 0.34472167]
[0.30815179 0.33241613 0.35943208]]
=== 步骤5: 最终输出 Output (每个词融合全局信息后的新表示) ===
[[0.55158713 0.49825904]
[0.5443457 0.50918687]
[0.53701315 0.52096187]]
=== 检查每行权重和 ===
[1. 1. 1.]<em id="__mceDel"> </em>




注意力机制